Giới Thiệu Về Các Loại Dữ Liệu: Structured, Unstructured, và Semi-Structured
Khám phá ba loại dữ liệu chính trong kỹ thuật dữ liệu: dữ liệu có cấu trúc, dữ liệu không có cấu trúc và dữ liệu bán cấu trúc, cùng các đặc điểm và ví dụ minh họa.

Trong lĩnh vực kỹ thuật dữ liệu, hiểu rõ về các loại dữ liệu là nền tảng quan trọng giúp bạn thành công, đặc biệt khi chuẩn bị cho các kỳ thi chuyên môn.
Bài viết này sẽ cung cấp cái nhìn tổng quan về ba loại dữ liệu chính: Structured Data (Dữ liệu có cấu trúc), Unstructured Data (Dữ liệu không có cấu trúc), và Semi-Structured Data (Dữ liệu bán cấu trúc).
Dữ liệu có cấu trúc (Structured Data)
Dữ liệu có cấu trúc là loại dữ liệu được tổ chức theo một cấu trúc hoặc lược đồ rõ ràng. Loại dữ liệu này thường được lưu trữ trong các cơ sở dữ liệu quan hệ, nơi dữ liệu được sắp xếp thành các hàng và cột với các kiểu dữ liệu nhất định.
Các đặc điểm chính của dữ liệu có cấu trúc bao gồm:
- Dễ dàng truy vấn: Có thể sử dụng các truy vấn SQL để truy vấn dữ liệu nhờ vào cấu trúc rõ ràng.
- Tổ chức trong bảng: Dữ liệu được sắp xếp thành các hàng và cột.
- Cấu trúc nhất quán: Không có sự bất ngờ về cấu trúc hoặc kiểu dữ liệu.
Ví dụ về dữ liệu có cấu trúc:
- Bảng dữ liệu trong các cơ sở dữ liệu như Oracle, MySQL, PostgreSQL.
- Tệp CSV với cấu trúc cột nhất quán.
- Bảng tính Excel được tổ chức tốt.
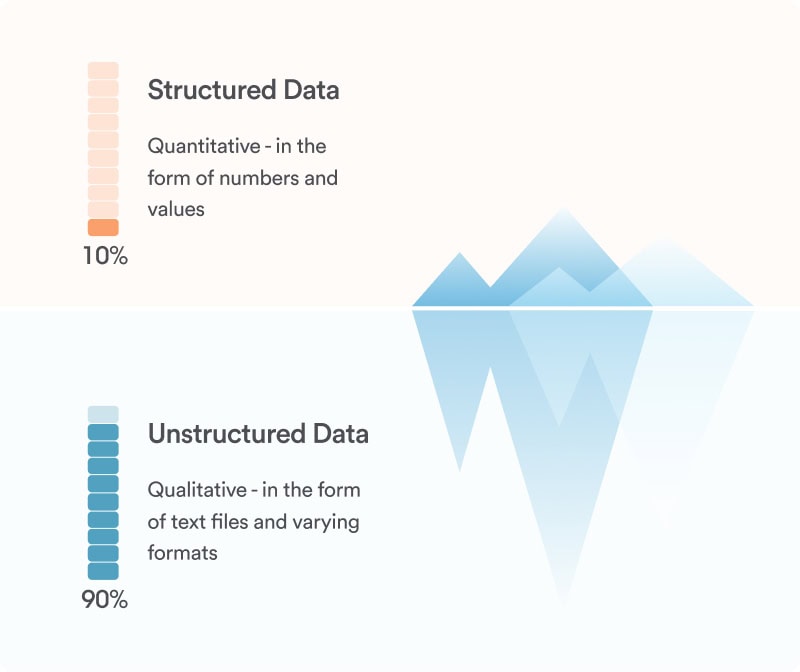
Trong khi dữ liệu có cấu trúc dễ dàng truy vấn, dữ liệu không có cấu trúc đòi hỏi quá trình xử lý trước. Dữ liệu bán cấu trúc mang lại sự linh hoạt nhưng vẫn yêu cầu công việc phân tích nhất định.
Dữ liệu không có cấu trúc (Unstructured Data)
Dữ liệu không có cấu trúc là dữ liệu không theo một lược đồ hoặc cấu trúc xác định. Việc truy vấn loại dữ liệu này thường đòi hỏi phải xử lý trước để trích xuất thông tin và xây dựng các chỉ mục.
- Đa dạng định dạng: Dữ liệu không có cấu trúc có thể xuất hiện dưới nhiều dạng khác nhau như văn bản thô, hình ảnh, video, hoặc âm thanh.
- Khó truy vấn trực tiếp: Cần phải trích xuất metadata hoặc phân tích nội dung để hiểu và sử dụng dữ liệu.
Ví dụ về dữ liệu không có cấu trúc:
- Tệp văn bản thô như tài liệu Wikipedia.
- File hình ảnh, âm thanh, hoặc video.
- Email và tài liệu xử lý văn bản.
Dữ liệu bán cấu trúc (Semi-Structured Data)
Dữ liệu bán cấu trúc nằm giữa hai loại trên, không hoàn toàn có cấu trúc nhưng vẫn chứa các yếu tố có thể xác định được thông qua thẻ hoặc hệ thống phân cấp.
- Cấu trúc linh hoạt: Dữ liệu có thể chứa các thành phần khác nhau nhưng vẫn có một số mức độ tổ chức.
- Khả năng trích xuất thông tin: Cần thực hiện một số công việc để phân tích và sắp xếp dữ liệu.
Ví dụ về dữ liệu bán cấu trúc:
- Tệp XML và JSON, nơi có thể chứa các lược đồ khác nhau.
- Header email, chứa thông tin như ngày gửi, chủ đề.
- Log file từ Apache hoặc các dịch vụ khác, nơi dữ liệu có thể không đồng nhất.
Kết luận
Hiểu rõ về các loại dữ liệu structured, unstructured, và semi-structured là rất quan trọng trong kỹ thuật dữ liệu. Mỗi loại dữ liệu có các đặc điểm riêng, yêu cầu các phương pháp xử lý khác nhau để trích xuất và sử dụng thông tin hiệu quả.
Trong khi dữ liệu có cấu trúc dễ dàng truy vấn, dữ liệu không có cấu trúc đòi hỏi quá trình xử lý trước. Dữ liệu bán cấu trúc mang lại sự linh hoạt nhưng vẫn yêu cầu công việc phân tích nhất định.
Nắm vững những khái niệm này sẽ giúp bạn xử lý dữ liệu hiệu quả hơn và chuẩn bị tốt cho các kỳ thi chuyên môn.
Bài viết liên quan
Bài 1 - Giới Thiệu Về Các Loại Dữ Liệu: Structured, Unstructured, và Semi-Structured
Bắt Đầu
Bài 2 - 3 Đặc Tính Của Dữ Liệu: Khối Lượng, Tốc Độ và Đa Dạng
Bắt Đầu
Bài 3 - Sự Khác Biệt Giữa Data Warehouse và Data Lake
Bắt Đầu
Bài 4 - Hiểu về Data Mesh: Xu Hướng Mới Trong Data Engineering
Bắt Đầu
Bài 5 - ETL và ELT: Hiểu Rõ Quy Trình Xử Lý Dữ Liệu Trong Data Warehouse và Data Lake
Bắt Đầu
Bài 6 - Các Nguồn Dữ Liệu và Định Dạng Dữ Liệu Quan Trọng trong Xử Lý Dữ Liệu
Bắt Đầu
Bài 7 - Mô hình dữ liệu – các khái niệm về Star Schema, Data Lineage và Schema Evolution
Bắt Đầu
Bài 8 - Tối ưu hóa hiệu suất cơ sở dữ liệu: Các kỹ thuật quan trọng để truy vấn nhanh và lưu trữ hiệu quả
Bắt Đầu
Bài 9 - Phương Pháp Lấy Mẫu Dữ Liệu (Data Sampling): Khái Niệm, Tầm Quan Trọng và Ứng Dụng
Bắt Đầu
Bài 10 - Hiểu về “Data Skew” (độ lệch dữ liệu) trong hệ thống phân tán
Bắt Đầu