ETL và ELT: Hiểu Rõ Quy Trình Xử Lý Dữ Liệu Trong Data Warehouse và Data Lake
ETL và ELT là hai quy trình quan trọng trong xử lý dữ liệu, giúp chuyển đổi dữ liệu từ nhiều nguồn khác nhau vào Data Warehouse hoặc Data Lake.

Trong thời đại công nghệ thông tin phát triển mạnh mẽ, dữ liệu trở thành một tài sản vô giá đối với các doanh nghiệp và tổ chức. Lượng dữ liệu khổng lồ phát sinh hàng ngày đòi hỏi một quy trình xử lý hiệu quả để chuyển đổi từ dữ liệu thô thành thông tin có giá trị.
Điều này làm nổi bật vai trò của các hệ thống Data Warehouse (Kho dữ liệu) và Data Lake (Hồ dữ liệu), nơi dữ liệu được tổ chức và lưu trữ theo cách có thể dễ dàng khai thác phục vụ cho việc phân tích. Để đảm bảo dữ liệu được nhập vào các hệ thống này một cách hợp lý, hai phương pháp quan trọng là ETL (Extract, Transform, Load) và ELT (Extract, Load, Transform) được sử dụng rộng rãi.
Trong bài viết này, chúng ta sẽ cùng tìm hiểu sâu hơn về hai quy trình này, khám phá cách thức hoạt động của chúng và đánh giá sự khác biệt giữa chúng trong bối cảnh hệ thống dữ liệu hiện đại.
ETL: Extract – Transform – Load
ETL là một quy trình xử lý dữ liệu truyền thống được sử dụng rộng rãi trong các hệ thống phân tích dữ liệu.
Nó bao gồm ba bước quan trọng:
- Trích xuất dữ liệu (Extract)
- Chuyển đổi dữ liệu (Transform)
- Tải dữ liệu lên kho dữ liệu (Load)
Quy trình này được áp dụng rộng rãi trong các hệ thống Data Warehouse, nơi dữ liệu được làm sạch và tổ chức trước khi lưu trữ nhằm đảm bảo hiệu quả phân tích.
Bước đầu tiên của ETL là trích xuất dữ liệu từ nhiều nguồn khác nhau như cơ sở dữ liệu quan hệ, API, hệ thống CRM hoặc tệp log. Sau khi thu thập dữ liệu, bước tiếp theo là chuyển đổi, bao gồm làm sạch, chuẩn hóa và hợp nhất dữ liệu để phù hợp với mô hình dữ liệu của kho dữ liệu. Cuối cùng, dữ liệu đã được chuẩn bị sẽ được tải lên kho dữ liệu để phân tích và sử dụng.
ELT: Extract – Load – Transform
ELT là một phương pháp xử lý dữ liệu hiện đại hơn, đặc biệt phù hợp với các hệ thống Big Data và Data Lake.
Không giống như ETL, quy trình ELT thực hiện việc tải dữ liệu thô lên hệ thống lưu trữ trước khi thực hiện các bước chuyển đổi. Điều này mang lại sự linh hoạt cao hơn vì dữ liệu có thể được lưu trữ dưới dạng nguyên bản và chỉ được xử lý khi cần thiết.
ELT phù hợp với các hệ thống phân tích dữ liệu lớn sử dụng các công cụ như Apache Spark, AWS Glue và Google Dataflow. Với phương pháp này, dữ liệu có thể được lưu trữ trong Data Lake ở định dạng thô, cho phép các nhà phân tích và khoa học dữ liệu thực hiện các phép chuyển đổi một cách linh hoạt dựa trên nhu cầu thực tế.
Chi tiết từng bước trong ETL và ELT
1. Extract – Trích Xuất Dữ Liệu
Bước trích xuất dữ liệu đóng vai trò quan trọng trong việc thu thập thông tin từ nhiều nguồn khác nhau. Dữ liệu có thể đến từ nhiều hệ thống khác nhau như cơ sở dữ liệu SQL, hệ thống CRM như Salesforce, tệp log từ máy chủ, hoặc API từ các dịch vụ bên thứ ba. Một số hệ thống có thể có cấu trúc dữ liệu rõ ràng, trong khi các nguồn khác có thể chứa dữ liệu phi cấu trúc hoặc bán cấu trúc như JSON hoặc XML.
Khi thực hiện trích xuất, điều quan trọng là đảm bảo tính toàn vẹn của dữ liệu, tránh mất mát hoặc trùng lặp. Ngoài ra, tốc độ trích xuất cũng là một yếu tố quan trọng, tùy thuộc vào yêu cầu thời gian thực hay xử lý theo lô. Các hệ thống có thể thực hiện trích xuất dữ liệu định kỳ theo giờ, theo ngày hoặc theo tuần, hoặc thậm chí sử dụng công nghệ streaming để trích xuất dữ liệu ngay khi nó phát sinh.
2. Transform – Chuyển Đổi Dữ Liệu
Sau khi dữ liệu được trích xuất, bước tiếp theo là chuyển đổi dữ liệu thành một định dạng phù hợp để phân tích. Giai đoạn này có thể bao gồm nhiều công đoạn khác nhau như làm sạch dữ liệu, chuẩn hóa định dạng, hợp nhất dữ liệu từ nhiều nguồn, và thực hiện các phép tính toán để tạo ra các thông tin tổng hợp.
Một trong những thách thức phổ biến trong giai đoạn này là xử lý dữ liệu bị thiếu, trong đó doanh nghiệp cần quyết định xem có nên loại bỏ dữ liệu không hợp lệ, thay thế bằng giá trị mặc định hay sử dụng phương pháp nội suy để điền vào chỗ trống.
Ngoài ra, một số dữ liệu có thể cần được mã hóa hoặc giải mã để bảo vệ thông tin nhạy cảm. Việc lựa chọn chiến lược chuyển đổi phù hợp sẽ ảnh hưởng đến chất lượng và hiệu suất của hệ thống phân tích dữ liệu.
Bước 1: Làm sạch dữ liệu (Data Cleansing):
- Xử lý dữ liệu lỗi: Phát hiện và sửa chữa các lỗi trong dữ liệu, chẳng hạn như lỗi chính tả, dữ liệu không hợp lệ hoặc dữ liệu bị sai.
- Loại bỏ dữ liệu trùng lặp: Xác định và xóa các bản sao không cần thiết.
- Điền dữ liệu thiếu (Imputation): Đối với những trường hợp dữ liệu bị thiếu, có thể điền giá trị mặc định hoặc ước lượng giá trị thay thế hợp lý.
Bước 2: Làm giàu dữ liệu (Data Enrichment):
- Kết hợp dữ liệu từ nhiều nguồn khác nhau để làm giàu thêm dữ liệu ban đầu. Ví dụ, có thể thêm thông tin từ một hệ thống khác hoặc từ các bảng dữ liệu bên ngoài để cung cấp thông tin bổ sung cho mỗi bản ghi.
Bước 3: Chuyển đổi định dạng (Format Conversion):
- Chuyển đổi định dạng ngày giờ: Dữ liệu ngày tháng có thể được lưu trữ dưới dạng chuỗi thô nhưng cần được chuyển đổi thành định dạng
datetimephù hợp. - Chuyển đổi kiểu dữ liệu: Dữ liệu văn bản có thể được chuyển thành kiểu số nguyên, dữ liệu nhị phân có thể được mã hóa lại dưới một dạng khác để phù hợp với yêu cầu của kho dữ liệu.
Bước 4: Tính toán và tổng hợp (Aggregation and Computation):
- Tính toán các giá trị tổng hợp như tổng, trung bình, min, max từ các dữ liệu thô. Ví dụ, tính tổng doanh thu hàng tháng từ dữ liệu giao dịch hàng ngày.
Bước 4: Mã hóa và giải mã dữ liệu (Encoding and Decoding):
- Một số dữ liệu có thể được nén hoặc mã hóa trước khi truyền tải. Cần phải giải mã hoặc giải nén để sử dụng, hoặc có thể mã hóa dữ liệu theo một định dạng khác trước khi lưu trữ.
Bước 5: Xử lý dữ liệu thiếu (Handling Missing Data):
- Quyết định cách xử lý các trường dữ liệu thiếu: có thể loại bỏ các dòng dữ liệu thiếu hoặc điền giá trị thay thế (imputation). Phương án xử lý này phụ thuộc vào yêu cầu kinh doanh và tính chất của dữ liệu.
3. Load – Tải Dữ Liệu
Bước cuối cùng của quy trình ETL hoặc ELT là tải dữ liệu vào hệ thống đích.
Đối với ETL, dữ liệu đã được xử lý và làm sạch trước khi lưu trữ vào Data Warehouse, giúp tối ưu hóa hiệu suất truy vấn. Ngược lại, với ELT, dữ liệu thô được lưu trữ vào Data Lake và chỉ được xử lý khi có nhu cầu truy vấn cụ thể.
Quá trình tải dữ liệu có thể được thực hiện theo lô hoặc theo dòng, tùy thuộc vào yêu cầu kinh doanh. Điều quan trọng là phải đảm bảo dữ liệu không bị mất mát trong quá trình tải, đồng thời có cơ chế giám sát để phát hiện và xử lý các lỗi có thể xảy ra.
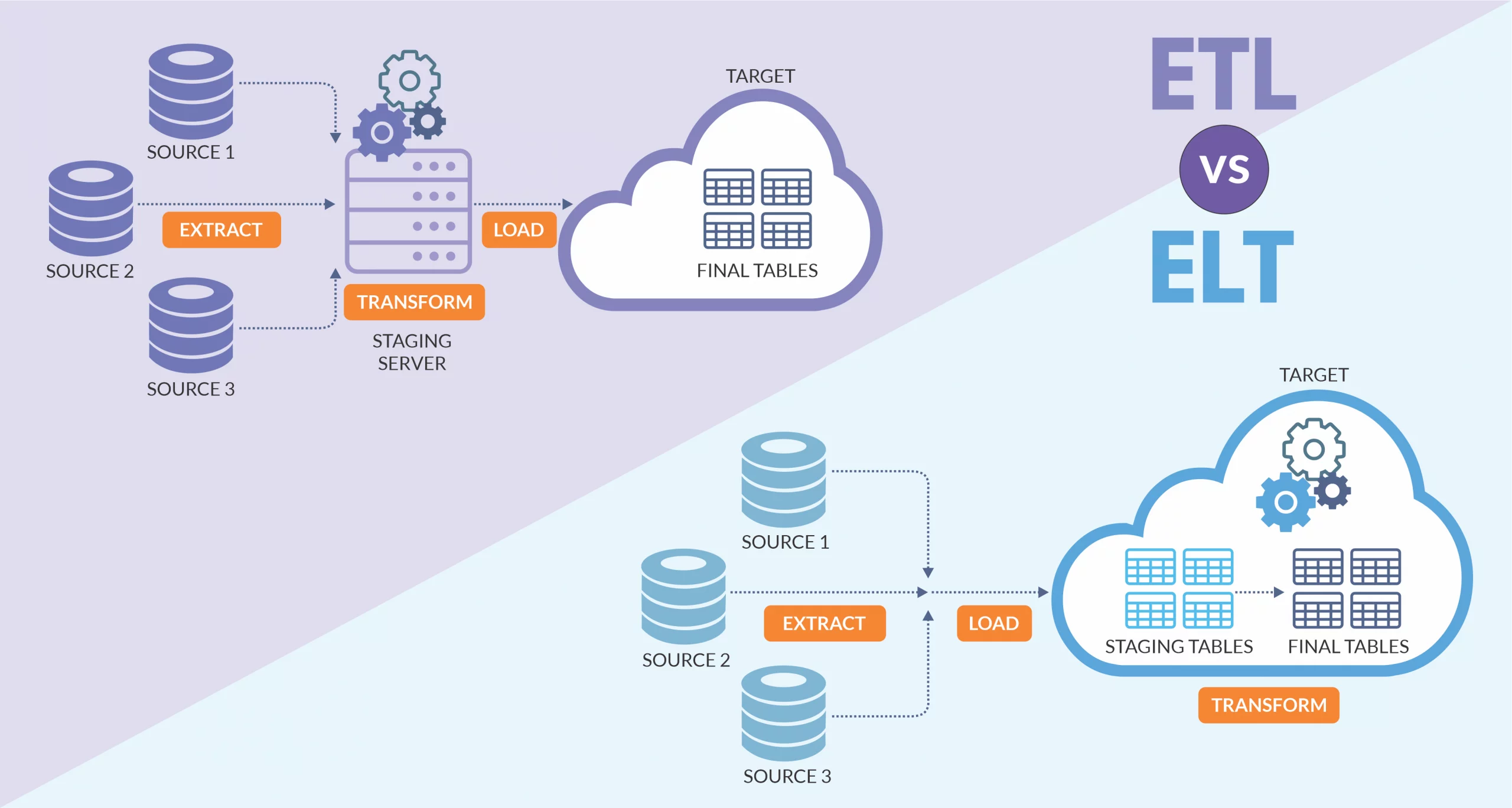
Hiểu rõ sự khác biệt giữa ETL và ELT sẽ giúp doanh nghiệp tối ưu hóa quy trình dữ liệu, từ đó nâng cao hiệu suất và khả năng khai thác giá trị từ dữ liệu.
So sánh ETL và ELT
| Đặc điểm | ETL | ELT |
|---|---|---|
| Trích xuất dữ liệu | Trích xuất trước | Trích xuất trước |
| Chuyển đổi dữ liệu | Trước khi tải lên | Sau khi tải lên |
| Lưu trữ dữ liệu thô | Không | Có |
| Phù hợp với | Data Warehouse | Data Lake |
| Hiệu suất | Cao với dữ liệu nhỏ và vừa | Tốt hơn với Big Data |
Công cụ hỗ trợ ETL và ELT
Hiện nay, có nhiều công cụ mạnh mẽ hỗ trợ quy trình ETL và ELT giúp doanh nghiệp dễ dàng triển khai các pipeline dữ liệu. Một số công cụ phổ biến bao gồm:
- AWS Glue – Dịch vụ ETL tự động của AWS.
- Apache Airflow – Công cụ điều phối quy trình làm việc dữ liệu.
- AWS Step Functions – Điều phối các tác vụ xử lý dữ liệu.
- Google Dataflow – Công cụ xử lý dữ liệu theo mô hình ETL và ELT.
- Microsoft Azure Data Factory – Dịch vụ quản lý ETL trên nền tảng Azure.
Kết luận
ETL và ELT đều là những quy trình quan trọng trong việc xử lý dữ liệu và đưa vào hệ thống phân tích. Trong khi ETL phù hợp với các hệ thống Data Warehouse cần dữ liệu đã chuẩn hóa trước khi lưu trữ, ELT là sự lựa chọn tối ưu cho Big Data nhờ khả năng lưu trữ dữ liệu thô linh hoạt.
Việc lựa chọn phương pháp nào phụ thuộc vào nhu cầu cụ thể của doanh nghiệp, khả năng hạ tầng và mục tiêu phân tích dữ liệu. Hiểu rõ sự khác biệt giữa ETL và ELT sẽ giúp doanh nghiệp tối ưu hóa quy trình dữ liệu, từ đó nâng cao hiệu suất và khả năng khai thác giá trị từ dữ liệu.
Bài viết liên quan

Bài 1 - Giới Thiệu Về Các Loại Dữ Liệu: Structured, Unstructured, và Semi-Structured
Bắt Đầu
Bài 2 - 3 Đặc Tính Của Dữ Liệu: Khối Lượng, Tốc Độ và Đa Dạng
Bắt Đầu
Bài 3 - Sự Khác Biệt Giữa Data Warehouse và Data Lake
Bắt Đầu
Bài 4 - Hiểu về Data Mesh: Xu Hướng Mới Trong Data Engineering
Bắt Đầu
Bài 5 - ETL và ELT: Hiểu Rõ Quy Trình Xử Lý Dữ Liệu Trong Data Warehouse và Data Lake
Bắt Đầu
Bài 6 - Các Nguồn Dữ Liệu và Định Dạng Dữ Liệu Quan Trọng trong Xử Lý Dữ Liệu
Bắt Đầu
Bài 7 - Mô hình dữ liệu – các khái niệm về Star Schema, Data Lineage và Schema Evolution
Bắt Đầu
Bài 8 - Tối ưu hóa hiệu suất cơ sở dữ liệu: Các kỹ thuật quan trọng để truy vấn nhanh và lưu trữ hiệu quả
Bắt Đầu