Các Nguồn Dữ Liệu và Định Dạng Dữ Liệu Quan Trọng trong Xử Lý Dữ Liệu
Tìm hiểu về các nguồn dữ liệu phổ biến như JDBC, ODBC, API, log files và streaming data, cùng các định dạng dữ liệu quan trọng như CSV, JSON, Avro và Parquet để tối ưu hóa quá trình xử lý và phân tích dữ liệu.

Trong thời đại dữ liệu bùng nổ, khả năng thu thập, lưu trữ và phân tích dữ liệu trở nên vô cùng quan trọng. Dữ liệu có thể đến từ nhiều nguồn khác nhau, mỗi nguồn có đặc điểm và phương thức truy xuất riêng. Đồng thời, dữ liệu cũng tồn tại dưới nhiều định dạng khác nhau, phục vụ cho từng mục đích cụ thể, từ truyền tải giữa các hệ thống, lưu trữ lâu dài, cho đến phân tích và trực quan hóa.
Việc nắm bắt các nguồn dữ liệu cũng như các định dạng phổ biến không chỉ giúp tối ưu hóa quá trình xử lý dữ liệu mà còn giúp lựa chọn công nghệ phù hợp với từng bài toán thực tế. Bài viết này sẽ giúp bạn hiểu rõ hơn về các nguồn dữ liệu chính và các định dạng dữ liệu quan trọng, từ đó có thể áp dụng một cách linh hoạt trong các hệ thống phân tích dữ liệu hiện đại.
Các Nguồn Dữ Liệu Phổ Biến
Dữ liệu có thể đến từ nhiều nguồn khác nhau, từ các hệ thống cơ sở dữ liệu truyền thống, các API của hệ thống bên ngoài, cho đến các luồng dữ liệu thời gian thực. Mỗi nguồn có cách thức truy xuất riêng, ảnh hưởng đến cách lưu trữ và xử lý dữ liệu sau này. Dưới đây là một số nguồn dữ liệu quan trọng mà bạn thường gặp trong thực tế.
1. Kết nối JDBC (Java Database Connectivity)
JDBC là một giao thức kết nối giúp truy xuất dữ liệu từ các hệ quản trị cơ sở dữ liệu quan hệ như MySQL, PostgreSQL, SQL Server, Oracle Database và nhiều hệ thống khác. JDBC cung cấp một giao diện chuẩn cho phép ứng dụng Java thực hiện các truy vấn SQL, cập nhật dữ liệu và thao tác với cơ sở dữ liệu theo cách thống nhất, bất kể hệ quản trị cơ sở dữ liệu là gì.
Một số đặc điểm quan trọng của JDBC:
- Nền tảng độc lập: Vì được xây dựng trên Java, JDBC có thể hoạt động trên bất kỳ nền tảng nào hỗ trợ Java, từ Windows, Linux, đến macOS. Điều này giúp cho các ứng dụng Java dễ dàng tích hợp với nhiều hệ thống khác nhau mà không cần lo lắng về tính tương thích.
- Phụ thuộc vào ngôn ngữ: Mặc dù nền tảng độc lập, nhưng JDBC chỉ có thể được sử dụng trong các ứng dụng Java. Nếu bạn sử dụng Python, C#, hoặc một ngôn ngữ khác, bạn sẽ cần một giải pháp thay thế như ODBC hoặc các thư viện kết nối đặc thù của ngôn ngữ đó.
- Ứng dụng thực tế: JDBC thường được sử dụng trong các ứng dụng doanh nghiệp, nơi Java là nền tảng chính để xây dựng các hệ thống backend, các ứng dụng web hoặc các giải pháp phân tích dữ liệu lớn cần kết nối trực tiếp với cơ sở dữ liệu quan hệ.
2. Kết nối ODBC (Open Database Connectivity)
ODBC là một giao diện lập trình ứng dụng (API) cung cấp một cách thống nhất để truy cập dữ liệu từ nhiều loại hệ thống quản trị cơ sở dữ liệu khác nhau. Không giống như JDBC, ODBC không bị ràng buộc với bất kỳ ngôn ngữ lập trình cụ thể nào, điều này giúp nó trở thành một lựa chọn phổ biến trong các hệ thống cần tính linh hoạt cao.
Một số đặc điểm chính của ODBC:
- Phụ thuộc vào nền tảng: Để sử dụng ODBC, bạn cần cài đặt các trình điều khiển (drivers) tương ứng với hệ quản trị cơ sở dữ liệu mà bạn đang kết nối. Điều này có thể dẫn đến việc phải quản lý nhiều phiên bản driver khác nhau cho từng hệ điều hành hoặc phiên bản cơ sở dữ liệu.
- Không phụ thuộc vào ngôn ngữ: Bạn có thể sử dụng ODBC với nhiều ngôn ngữ khác nhau như Python, C++, PHP, và R, giúp nó trở thành một giải pháp lý tưởng khi làm việc với các hệ thống đa ngôn ngữ.
- Ứng dụng thực tế: ODBC thường được sử dụng trong các hệ thống ETL (Extract, Transform, Load) để trích xuất dữ liệu từ nhiều nguồn khác nhau trước khi đưa vào kho dữ liệu tập trung.
Tìm hiểu thêm: Cơ sở dữ liệu là gì? Các khái niệm cơ bản
3. Dữ liệu từ tệp nhật ký (Log Files)
Nhiều hệ thống phần mềm, từ ứng dụng web, hệ thống giao dịch, đến các thiết bị IoT đều ghi lại dữ liệu dưới dạng tệp nhật ký (log files). Các tệp này chứa thông tin chi tiết về hoạt động của hệ thống, bao gồm lỗi, cảnh báo, sự kiện quan trọng và dữ liệu từ người dùng.
- Ưu điểm: Log files là một nguồn dữ liệu phong phú để phân tích hiệu suất hệ thống, phát hiện bất thường, và hỗ trợ khắc phục sự cố. Chúng cũng thường được sử dụng trong các hệ thống SIEM (Security Information and Event Management) để phát hiện mối đe dọa bảo mật.
- Thách thức: Dữ liệu log thường không có cấu trúc cố định, dẫn đến khó khăn trong việc xử lý và phân tích. Để làm việc với log files hiệu quả, bạn có thể sử dụng các công cụ như ELK Stack (Elasticsearch, Logstash, Kibana) hoặc Splunk để thu thập và trực quan hóa dữ liệu.
4. API của hệ thống bên ngoài
API (Application Programming Interface) là một phương thức tiêu chuẩn để trao đổi dữ liệu giữa các hệ thống khác nhau. Các dịch vụ web, ứng dụng SaaS (Software as a Service), và nền tảng dữ liệu lớn thường cung cấp API để người dùng có thể truy cập dữ liệu mà không cần trực tiếp kết nối vào cơ sở dữ liệu nội bộ.
- Ứng dụng thực tế: API thường được sử dụng để thu thập dữ liệu từ các nền tảng như Google Analytics, Twitter, Facebook, hoặc để tích hợp các hệ thống doanh nghiệp khác nhau trong một hạ tầng chung.
5. Luồng dữ liệu thời gian thực (Streaming Data)
Trong các hệ thống hiện đại, dữ liệu không chỉ được lưu trữ dưới dạng tĩnh mà còn có thể được xử lý theo thời gian thực. Các nền tảng như Apache Kafka và AWS Kinesis cho phép thu thập, xử lý và phân phối dữ liệu ngay khi nó được tạo ra.
- Ưu điểm: Streaming data giúp phân tích dữ liệu theo thời gian thực, từ đó đưa ra quyết định nhanh chóng, chẳng hạn như phát hiện gian lận tài chính hoặc tối ưu hóa hệ thống vận hành.
- Ứng dụng thực tế: Hệ thống giao dịch chứng khoán, giám sát mạng lưới IoT, và phân tích hành vi người dùng trong các nền tảng thương mại điện tử đều sử dụng dữ liệu streaming để cải thiện trải nghiệm và hiệu suất.
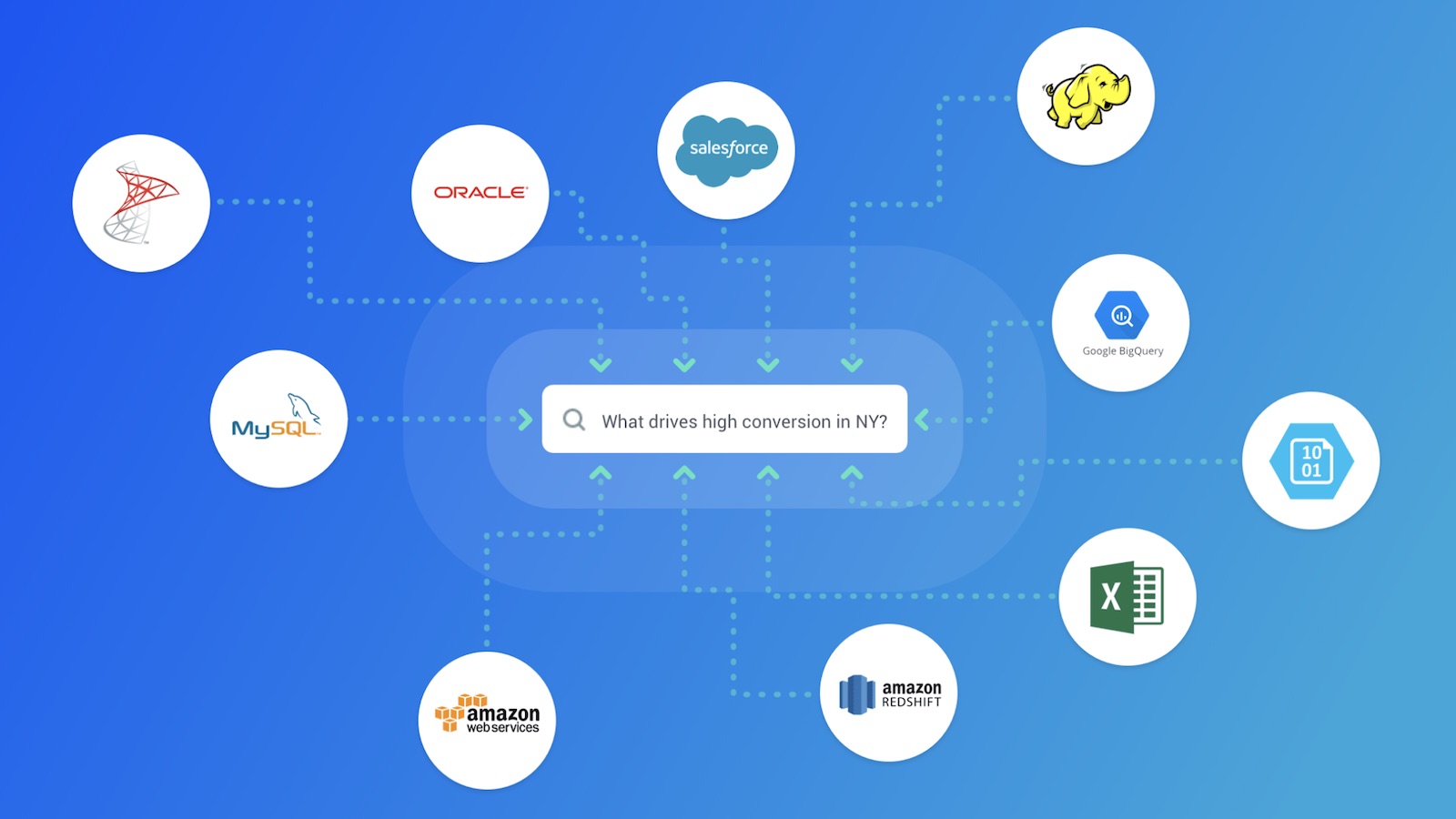
Dữ liệu có thể đến từ nhiều nguồn khác nhau, từ các hệ thống cơ sở dữ liệu truyền thống, các API của hệ thống bên ngoài, cho đến các luồng dữ liệu thời gian thực.
Các Định Dạng Dữ Liệu Quan Trọng
Dữ liệu không chỉ đến từ nhiều nguồn khác nhau mà còn được lưu trữ và truyền tải theo nhiều định dạng tùy thuộc vào mục đích sử dụng. Việc lựa chọn định dạng dữ liệu phù hợp có thể ảnh hưởng đáng kể đến hiệu suất xử lý, khả năng mở rộng và tính dễ sử dụng của hệ thống. Dưới đây là những định dạng dữ liệu quan trọng và ứng dụng của chúng trong thực tế.
1. CSV (Comma-Separated Values)
CSV là một định dạng phổ biến nhất để lưu trữ và trao đổi dữ liệu trong môi trường kinh doanh và khoa học dữ liệu. Đây là một tệp văn bản đơn giản, trong đó mỗi dòng đại diện cho một bản ghi, và các giá trị trong dòng được phân tách bằng dấu phẩy (,) hoặc một ký tự đặc biệt khác như tab (\t) hoặc dấu gạch đứng (|).
Ưu điểm:
- Đơn giản và dễ đọc: Vì là định dạng văn bản thuần túy, CSV có thể dễ dàng đọc được bằng con người và mở bằng các trình soạn thảo văn bản thông thường như Notepad hoặc Excel.
- Tính tương thích cao: Hầu hết các hệ thống quản lý cơ sở dữ liệu (SQL), bảng tính (Excel, Google Sheets), và thư viện khoa học dữ liệu như Pandas (Python) đều hỗ trợ CSV.
- Dễ dàng nhập/xuất dữ liệu: CSV thường được sử dụng làm định dạng trung gian để di chuyển dữ liệu giữa các hệ thống.
Nhược điểm:
- Không hỗ trợ cấu trúc dữ liệu phức tạp: Chỉ hoạt động tốt với dữ liệu có cấu trúc dạng bảng, không thể lưu trữ danh sách lồng nhau hoặc các mối quan hệ phức tạp.
- Không tối ưu cho hiệu suất: Do không được nén và không có schema đi kèm, CSV có thể tốn nhiều dung lượng lưu trữ hơn các định dạng khác.
- Xử lý dữ liệu lớn có thể chậm: Khi làm việc với hàng triệu hoặc hàng tỷ dòng dữ liệu, việc đọc và ghi từ tệp CSV có thể kém hiệu quả so với các định dạng nhị phân tối ưu hơn.
Ứng dụng thực tế:
- Xuất/nhập dữ liệu từ cơ sở dữ liệu SQL và các hệ thống bảng tính như Excel.
- Lưu trữ dữ liệu nhỏ đến trung bình trong các hệ thống ETL.
- Dữ liệu giao dịch hoặc báo cáo được lưu tạm thời trước khi nhập vào hệ thống chính.
2. JSON (JavaScript Object Notation)
JSON là một định dạng phổ biến trong phát triển ứng dụng và trao đổi dữ liệu giữa các hệ thống. Khác với CSV, JSON sử dụng cấu trúc dữ liệu dựa trên cặp key-value, giúp lưu trữ dữ liệu có cấu trúc hoặc bán cấu trúc một cách linh hoạt.
Ưu điểm:
- Hỗ trợ cấu trúc dữ liệu lồng nhau: JSON có thể lưu trữ danh sách, đối tượng lồng nhau, giúp biểu diễn các mối quan hệ phức tạp giữa các dữ liệu.
- Dễ đọc, dễ parse: JSON có cú pháp đơn giản, dễ hiểu và có thể được parse nhanh chóng bằng nhiều ngôn ngữ lập trình như JavaScript, Python, Java.
- Tương thích với API và web services: Hầu hết các API hiện nay (RESTful APIs) sử dụng JSON làm định dạng chính để truyền tải dữ liệu giữa frontend và backend.
- Hỗ trợ NoSQL databases: Các hệ cơ sở dữ liệu như MongoDB, CouchDB sử dụng JSON để lưu trữ và truy vấn dữ liệu.
Nhược điểm:
- Chiếm nhiều dung lượng hơn so với các định dạng nhị phân: Vì lưu trữ dữ liệu dưới dạng văn bản, JSON thường lớn hơn so với các định dạng như Avro hoặc Parquet.
- Không được tối ưu cho truy vấn dữ liệu lớn: JSON phù hợp cho dữ liệu có cấu trúc động nhưng khi xử lý dữ liệu lớn, tốc độ truy vấn có thể bị ảnh hưởng.
- Thiếu schema cố định: Mặc dù tính linh hoạt cao, việc thiếu schema có thể gây khó khăn khi xử lý dữ liệu từ nhiều nguồn khác nhau.
Ứng dụng thực tế:
- Trao đổi dữ liệu giữa máy chủ và trình duyệt web thông qua API.
- Lưu trữ cấu hình phần mềm, file settings.
- Hệ thống NoSQL như MongoDB sử dụng JSON làm định dạng lưu trữ chính.
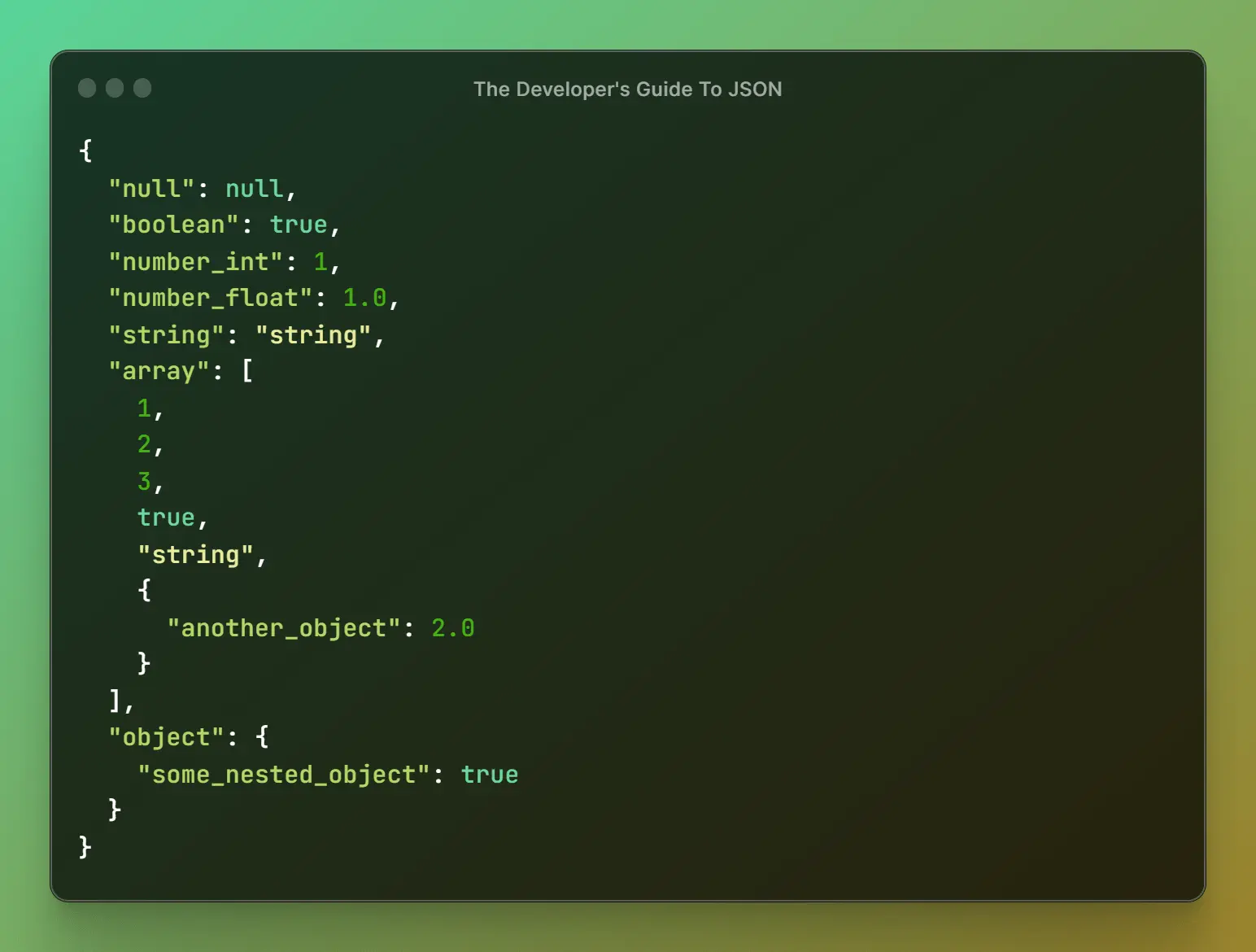
Khác với CSV, JSON sử dụng cấu trúc dữ liệu dựa trên cặp key-value, giúp lưu trữ dữ liệu có cấu trúc hoặc bán cấu trúc một cách linh hoạt.
3. Avro
Avro là một định dạng dữ liệu nhị phân được phát triển bởi Apache, chuyên dùng trong hệ thống xử lý dữ liệu lớn. Điểm đặc biệt của Avro là nó lưu trữ cả dữ liệu và schema trong cùng một tệp, giúp hệ thống dễ dàng đọc dữ liệu mà không cần biết trước cấu trúc.
Ưu điểm:
- Hiệu quả về dung lượng: Vì là định dạng nhị phân, Avro có dung lượng nhỏ hơn JSON hoặc CSV.
- Tích hợp schema: Schema được lưu cùng dữ liệu, giúp hệ thống dễ dàng thay đổi và cập nhật cấu trúc dữ liệu mà không làm mất dữ liệu cũ.
- Tối ưu cho dữ liệu lớn: Avro được thiết kế cho các hệ thống xử lý dữ liệu phân tán như Hadoop, Kafka, Spark.
Nhược điểm:
- Không dễ đọc bằng con người: Vì dữ liệu được lưu ở dạng nhị phân, việc kiểm tra nội dung Avro yêu cầu các công cụ hỗ trợ.
- Không phù hợp với các hệ thống nhỏ: Nếu dữ liệu không thay đổi thường xuyên, việc lưu schema trong mỗi tệp có thể gây lãng phí dung lượng.
Ứng dụng thực tế:
- Xử lý dữ liệu trong Apache Kafka, Apache Spark, Apache Flink và Hadoop.
- Truyền tải dữ liệu giữa các hệ thống với hiệu suất cao.
4. Parquet
Parquet là một định dạng dữ liệu lưu trữ theo cột thay vì theo dòng như CSV hay JSON. Điều này giúp tăng tốc độ truy vấn khi chỉ cần đọc một số cột thay vì toàn bộ dữ liệu.
Ưu điểm:
- Tối ưu hóa cho phân tích dữ liệu: Nếu truy vấn chỉ cần một số cột nhất định, Parquet có thể tăng tốc đáng kể so với các định dạng lưu trữ theo dòng.
- Nén dữ liệu hiệu quả: Vì dữ liệu cùng loại được lưu chung một nơi, các thuật toán nén có thể hoạt động hiệu quả hơn.
- Hỗ trợ tốt cho hệ thống phân tán: Parquet được thiết kế để chạy tốt trên Hadoop, Spark, Redshift Spectrum.
Nhược điểm:
- Không thân thiện với con người: Parquet không thể mở trực tiếp bằng các trình soạn thảo văn bản thông thường.
- Không phù hợp cho dữ liệu có cấu trúc động: Nếu dữ liệu có schema thay đổi thường xuyên, Parquet có thể không linh hoạt bằng JSON hoặc Avro.
Ứng dụng thực tế:
- Lưu trữ và truy vấn dữ liệu lớn trong hệ thống phân tích như Hadoop, Apache Spark, Redshift Spectrum.
- Tăng tốc truy vấn trong hệ thống Business Intelligence (BI).
Kết Luận
Như vậy, việc hiểu rõ về các nguồn dữ liệu cũng như các định dạng dữ liệu phổ biến sẽ giúp bạn có cái nhìn toàn diện hơn về cách thức thu thập, lưu trữ và xử lý dữ liệu trong các hệ thống thực tế.
- Nếu bạn đang làm việc với cơ sở dữ liệu quan hệ, hãy xem xét JDBC hoặc ODBC.
- Nếu bạn xử lý dữ liệu phi cấu trúc, hãy tìm hiểu về log files hoặc API.
- Nếu bạn cần phân tích dữ liệu theo thời gian thực, các nền tảng streaming như Kafka hoặc Kinesis sẽ là lựa chọn phù hợp.
Việc chọn nguồn dữ liệu và định dạng phù hợp sẽ ảnh hưởng rất lớn đến hiệu suất, khả năng mở rộng và khả năng phân tích của hệ thống dữ liệu mà bạn đang xây dựng.
Bài viết liên quan

Bài 1 - Giới Thiệu Về Các Loại Dữ Liệu: Structured, Unstructured, và Semi-Structured
Bắt Đầu
Bài 2 - 3 Đặc Tính Của Dữ Liệu: Khối Lượng, Tốc Độ và Đa Dạng
Bắt Đầu
Bài 3 - Sự Khác Biệt Giữa Data Warehouse và Data Lake
Bắt Đầu
Bài 4 - Hiểu về Data Mesh: Xu Hướng Mới Trong Data Engineering
Bắt Đầu
Bài 5 - ETL và ELT: Hiểu Rõ Quy Trình Xử Lý Dữ Liệu Trong Data Warehouse và Data Lake
Bắt Đầu
Bài 6 - Các Nguồn Dữ Liệu và Định Dạng Dữ Liệu Quan Trọng trong Xử Lý Dữ Liệu
Bắt Đầu
Bài 7 - Mô hình dữ liệu – các khái niệm về Star Schema, Data Lineage và Schema Evolution
Bắt Đầu
Bài 8 - Tối ưu hóa hiệu suất cơ sở dữ liệu: Các kỹ thuật quan trọng để truy vấn nhanh và lưu trữ hiệu quả
Bắt Đầu
Bài 9 - Phương Pháp Lấy Mẫu Dữ Liệu (Data Sampling): Khái Niệm, Tầm Quan Trọng và Ứng Dụng
Bắt Đầu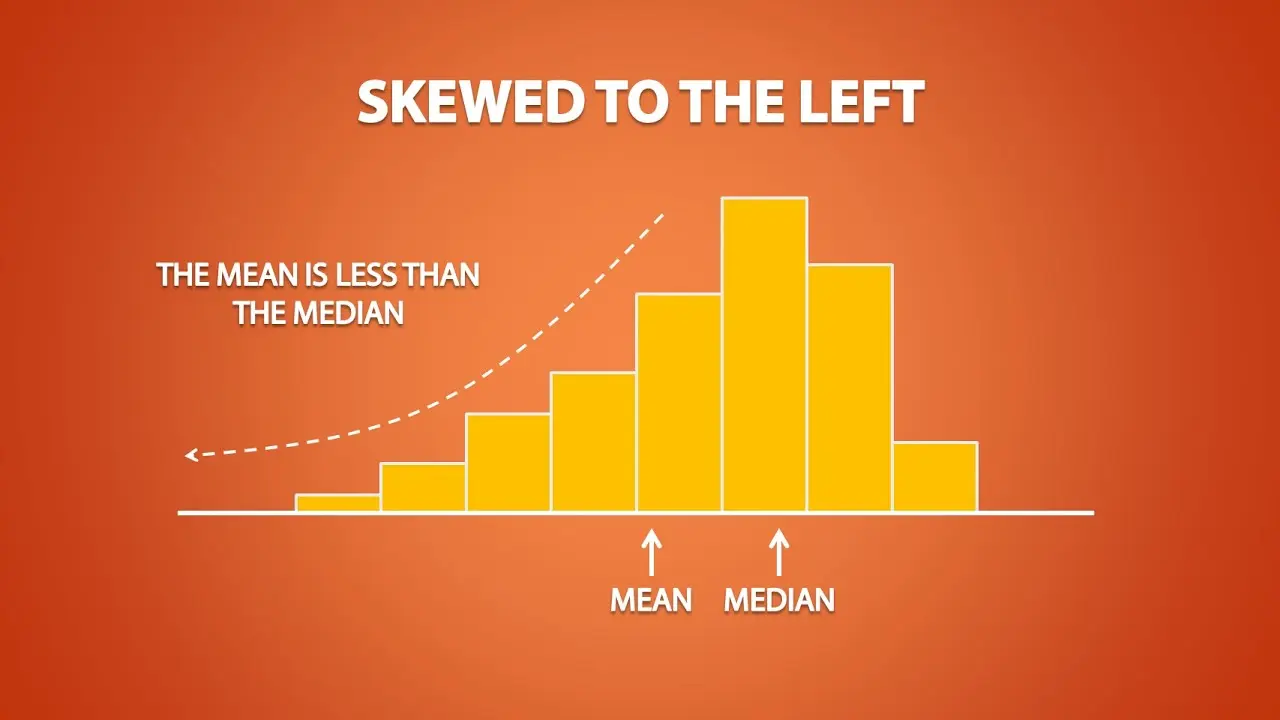
Bài 10 - Hiểu về “Data Skew” (độ lệch dữ liệu) trong hệ thống phân tán
Bắt Đầu