Hiểu về Data Mesh: Xu Hướng Mới Trong Data Engineering
Data Mesh là mô hình quản lý dữ liệu phân tán, giúp tổ chức tối ưu hóa quyền sở hữu, truy cập và quản trị dữ liệu theo miền, nâng cao tính linh hoạt và chất lượng dữ liệu.

Trong thế giới dữ liệu ngày nay, một khái niệm đang thu hút nhiều sự chú ý trong lĩnh vực Data Engineering là Data Mesh. Đây không phải là một công nghệ cụ thể mà là một triết lý về cách tổ chức, quản lý và truy cập dữ liệu trong một tổ chức lớn.
Data Mesh không tập trung vào cách thức lưu trữ hay xử lý dữ liệu mà tập trung vào quyền sở hữu dữ liệu, tổ chức và quản trị dữ liệu. Điều này giúp cải thiện khả năng mở rộng, linh hoạt và hiệu quả sử dụng dữ liệu trong các doanh nghiệp hiện đại.
Data Mesh Là Gì?
Data Mesh là một mô hình quản lý dữ liệu phân tán, trong đó các nhóm hoặc phòng ban trong tổ chức sở hữu và quản lý dữ liệu của chính họ.
Thay vì tập trung toàn bộ dữ liệu vào một nhóm trung tâm duy nhất, mô hình này phân quyền quản lý dữ liệu cho các nhóm chuyên môn, những người hiểu rõ nhất về dữ liệu mà họ đang thu thập và sử dụng.
Mỗi nhóm trong tổ chức không chỉ chịu trách nhiệm duy trì dữ liệu của họ mà còn cần cung cấp dữ liệu đó dưới dạng “data product” (sản phẩm dữ liệu) cho các nhóm khác có nhu cầu sử dụng. Điều này giúp tránh tình trạng tập trung quyền kiểm soát vào một nhóm duy nhất, giảm thiểu tình trạng tắc nghẽn và tối ưu hóa khả năng khai thác dữ liệu trên quy mô lớn.
Tìm hiểu thêm: Khám Phá Thế Giới Dữ Liệu: Tất Cả Những Gì Bạn Cần Biết
Các Thành Phần Cốt Lõi của Data Mesh
Mô hình Data Mesh dựa trên bốn nguyên tắc chính, giúp đảm bảo việc quản lý và khai thác dữ liệu hiệu quả:
Nguyên tắc 1: Quản lý dữ liệu theo miền (Domain-Oriented Data Ownership)
Các nhóm kinh doanh (domain teams) sở hữu và quản lý dữ liệu mà họ hiểu rõ nhất. Điều này giúp đảm bảo tính chính xác và chất lượng dữ liệu cao hơn do được kiểm soát bởi các chuyên gia có kiến thức sâu sắc về dữ liệu cụ thể của họ.
Ví dụ, phòng Kinh doanh quản lý dữ liệu bán hàng, phòng Nhân sự quản lý dữ liệu nhân viên. Nhờ đó, các nhóm có thể tối ưu hóa quy trình làm việc và cải thiện khả năng ra quyết định dựa trên dữ liệu.
Nguyên tắc 2: Dữ liệu như một sản phẩm (Data as a Product)
Dữ liệu không chỉ là một tập hợp thông tin mà cần được tổ chức như một sản phẩm có tài liệu, SLA (Service Level Agreement) và đảm bảo chất lượng. Điều này có nghĩa là mỗi sản phẩm dữ liệu cần phải có mô tả rõ ràng, khả năng truy cập dễ dàng và đảm bảo tính toàn vẹn để có thể sử dụng hiệu quả.
Khi dữ liệu được quản lý như một sản phẩm, các nhóm có thể dễ dàng chia sẻ dữ liệu với nhau mà không cần sự can thiệp phức tạp từ đội ngũ IT trung tâm.
Nguyên tắc 3: Hạ tầng dữ liệu tự phục vụ (Self-serve Data Infrastructure as a Platform)
Các nhóm có quyền truy cập vào các công cụ và nền tảng hỗ trợ họ tạo, quản lý và chia sẻ dữ liệu một cách dễ dàng. Điều này giúp giảm bớt sự phụ thuộc vào nhóm kỹ thuật trung tâm và tăng tốc quá trình khai thác dữ liệu.
Ví dụ: AWS cung cấp các dịch vụ như AWS Glue, Lake Formation, S3 để hỗ trợ triển khai Data Mesh. Nhờ các dịch vụ này, các nhóm có thể nhanh chóng tạo ra các sản phẩm dữ liệu mà không cần đầu tư lớn vào hạ tầng riêng lẻ.
Nguyên tắc 4: Quản trị dữ liệu liên kết (Federated Computational Governance)
Dù dữ liệu được phân quyền quản lý, vẫn cần một bộ quy tắc chung để đảm bảo tính bảo mật, tuân thủ và quản trị dữ liệu hợp lý trên toàn tổ chức.
Quy trình này có thể bao gồm các chính sách về quyền truy cập, mã hóa dữ liệu, tuân thủ các quy định pháp lý và đảm bảo rằng mọi sản phẩm dữ liệu đều đáp ứng các tiêu chuẩn chất lượng chung.
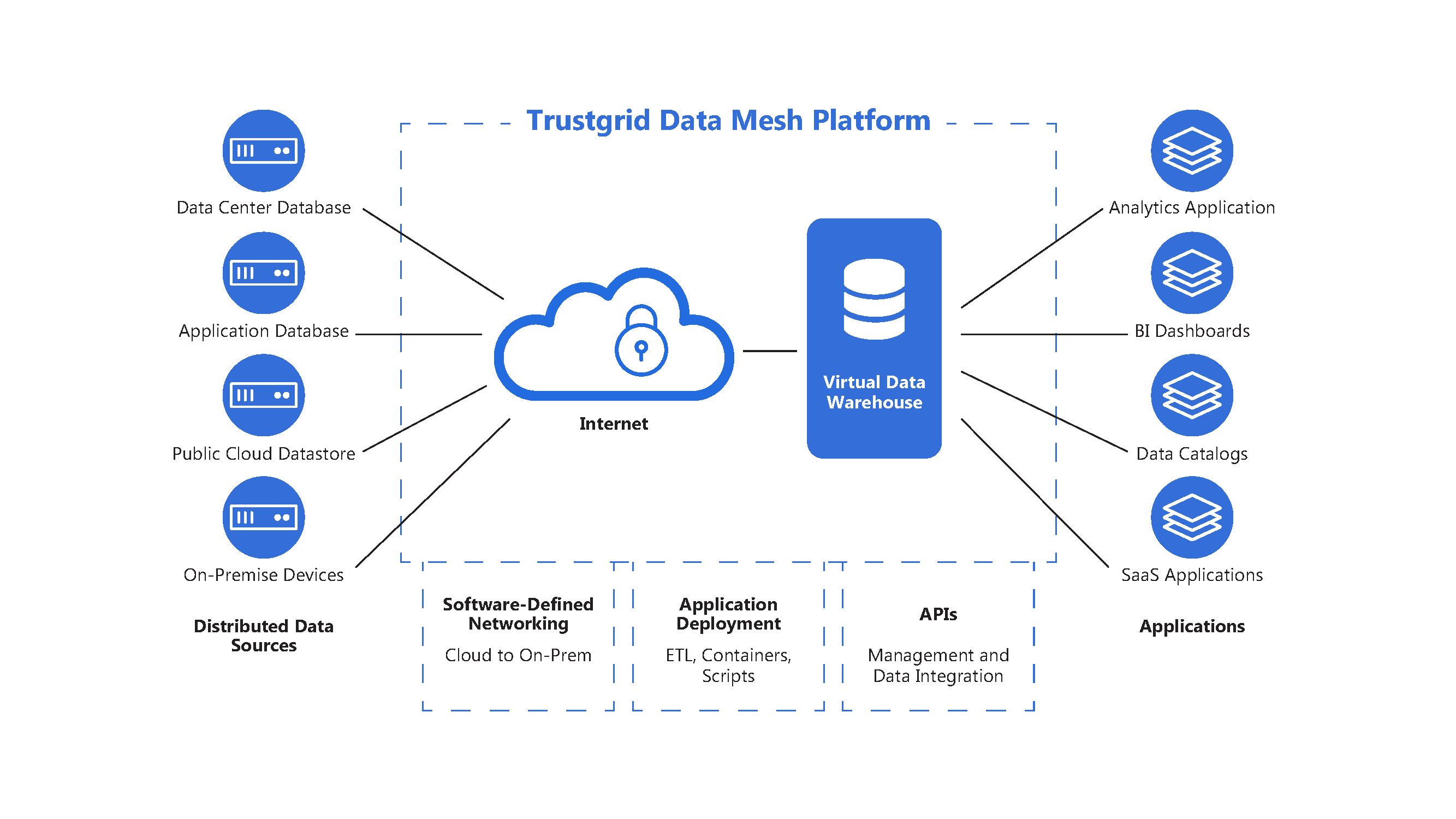
Các nhóm có quyền truy cập vào các công cụ và nền tảng hỗ trợ họ tạo, quản lý và chia sẻ dữ liệu một cách dễ dàng.
Lợi Ích Của Data Mesh
Áp dụng Data Mesh mang lại nhiều lợi ích quan trọng cho tổ chức:
- Tăng tính linh hoạt và mở rộng: Không bị phụ thuộc vào một nhóm trung tâm duy nhất, giúp tổ chức dễ dàng mở rộng quy mô mà không làm chậm tiến trình quản lý dữ liệu.
- Nâng cao chất lượng dữ liệu: Các nhóm chuyên môn sở hữu dữ liệu của mình nên có thể quản lý và duy trì dữ liệu tốt hơn, giảm thiểu sai sót và lỗi dữ liệu.
- Tối ưu hóa việc khai thác dữ liệu: Dữ liệu được cung cấp dưới dạng sản phẩm giúp dễ dàng truy cập và sử dụng hơn, hỗ trợ các nhóm phân tích và ra quyết định nhanh hơn.
- Giảm gánh nặng cho nhóm IT trung tâm: Khi các nhóm có thể tự phục vụ nhu cầu dữ liệu của họ, nhóm IT không còn phải đảm nhiệm quá nhiều yêu cầu truy xuất dữ liệu, giúp họ tập trung vào các nhiệm vụ quan trọng hơn.
Tìm hiểu thêm: Tư Duy Dữ Liệu: Lợi Ích, Các Yếu Tố Cơ Bản Và Tầm Quan Trọng Trong Kỷ Nguyên Số
AWS và Data Mesh
AWS cung cấp một loạt các công cụ giúp triển khai mô hình Data Mesh một cách hiệu quả:
- AWS Glue: Cung cấp khả năng lập danh mục dữ liệu tập trung, giúp các nhóm dễ dàng tìm kiếm và truy cập dữ liệu phù hợp.
- AWS Lake Formation: Giúp tổ chức và quản lý quyền truy cập dữ liệu, đảm bảo tính bảo mật và tuân thủ quy tắc.
- Amazon S3: Lưu trữ dữ liệu linh hoạt và mở rộng, giúp các nhóm có thể dễ dàng chia sẻ và quản lý dữ liệu.
Các dịch vụ này giúp các tổ chức triển khai Data Mesh mà không cần xây dựng toàn bộ hạ tầng từ đầu, tiết kiệm chi phí và tăng tốc quá trình áp dụng mô hình này vào thực tiễn.
Tìm hiểu thêm: Sự Khác Biệt Giữa Data Warehouse và Data Lake
Kết Luận
Data Mesh là một cách tiếp cận hiện đại giúp tổ chức quản lý dữ liệu hiệu quả hơn trong môi trường dữ liệu phức tạp. Thay vì tập trung dữ liệu tại một bộ phận trung tâm, Data Mesh phân quyền quản lý cho các nhóm chuyên môn, giúp nâng cao hiệu quả khai thác dữ liệu.
Với sự hỗ trợ từ các nền tảng như AWS, các tổ chức có thể triển khai Data Mesh dễ dàng hơn, giúp tối ưu hóa việc sử dụng dữ liệu và tạo ra giá trị thực sự từ dữ liệu của họ. Khi được thực hiện đúng cách, Data Mesh không chỉ cải thiện khả năng quản lý dữ liệu mà còn giúp tổ chức tận dụng tối đa tiềm năng của dữ liệu trong kỷ nguyên số.
Bài viết liên quan

Bài 1 - Giới Thiệu Về Các Loại Dữ Liệu: Structured, Unstructured, và Semi-Structured
Bắt Đầu
Bài 2 - 3 Đặc Tính Của Dữ Liệu: Khối Lượng, Tốc Độ và Đa Dạng
Bắt Đầu
Bài 3 - Sự Khác Biệt Giữa Data Warehouse và Data Lake
Bắt Đầu
Bài 4 - Hiểu về Data Mesh: Xu Hướng Mới Trong Data Engineering
Bắt Đầu
Bài 5 - ETL và ELT: Hiểu Rõ Quy Trình Xử Lý Dữ Liệu Trong Data Warehouse và Data Lake
Bắt Đầu
Bài 6 - Các Nguồn Dữ Liệu và Định Dạng Dữ Liệu Quan Trọng trong Xử Lý Dữ Liệu
Bắt Đầu
Bài 7 - Mô hình dữ liệu – các khái niệm về Star Schema, Data Lineage và Schema Evolution
Bắt Đầu
Bài 8 - Tối ưu hóa hiệu suất cơ sở dữ liệu: Các kỹ thuật quan trọng để truy vấn nhanh và lưu trữ hiệu quả
Bắt Đầu
Bài 9 - Phương Pháp Lấy Mẫu Dữ Liệu (Data Sampling): Khái Niệm, Tầm Quan Trọng và Ứng Dụng
Bắt Đầu
Bài 10 - Hiểu về “Data Skew” (độ lệch dữ liệu) trong hệ thống phân tán
Bắt Đầu