Sự Khác Biệt Giữa Data Warehouse và Data Lake
Khám phá sự khác biệt giữa Data Warehouse và Data Lake, hai giải pháp quản lý dữ liệu phổ biến, để chọn lựa phù hợp cho doanh nghiệp của bạn.

Trong lĩnh vực quản lý dữ liệu, hai khái niệm “Data Warehouse” và “Data Lake” thường được nhắc đến. Vậy chúng khác nhau như thế nào và khi nào nên sử dụng một trong hai? Hãy cùng tìm hiểu.
Data Warehouse là gì?
Data Warehouse (Kho dữ liệu) là một kho lưu trữ tập trung, được thiết kế để tối ưu hóa cho các truy vấn phức tạp và phân tích dữ liệu. Dữ liệu trong Data Warehouse được tổ chức theo cấu trúc rõ ràng và thường được lưu trữ dưới dạng bảng trong các hệ quản trị cơ sở dữ liệu quan hệ (RDBMS).
Đặc điểm của Data Warehouse:
- Dữ liệu có cấu trúc: Dữ liệu được làm sạch, biến đổi và nạp vào kho dữ liệu theo một cấu trúc định sẵn.
- Quá trình ETL: Sử dụng quá trình Extract, Transform, Load (ETL) để trích xuất dữ liệu từ nguồn, biến đổi dữ liệu, và tải vào hệ thống.
- Tối ưu hóa cho truy vấn phức tạp: Data Warehouse được thiết kế để hỗ trợ các truy vấn phức tạp và phân tích dữ liệu.
Ví dụ: Amazon Redshift, Google BigQuery, Microsoft Azure SQL Data Warehouse.
Khi nào nên sử dụng Data Warehouse?
- Khi bạn có dữ liệu có cấu trúc và cần các truy vấn nhanh và phức tạp.
- Phân tích kinh doanh và báo cáo là trọng tâm chính.
Tìm hiểu thêm: Data Warehouse: Bí Quyết Tận Dụng Dữ Liệu Để Tối Ưu Doanh Nghiệp
Data Lake là gì?
Data Lake (Hồ dữ liệu) là một kho lưu trữ lớn, chứa dữ liệu thô với nhiều định dạng khác nhau, bao gồm dữ liệu có cấu trúc, bán cấu trúc và phi cấu trúc.
Đặc điểm của Data Lake:
- Lưu trữ dữ liệu thô: Dữ liệu được lưu trữ nguyên bản, không qua xử lý hoặc xử lý tối thiểu.
- Quá trình ELT: Sử dụng Extract, Load, Transform (ELT), dữ liệu được trích xuất và tải vào kho trước khi biến đổi khi cần thiết.
- Đa dạng loại dữ liệu: Có thể lưu trữ mọi loại dữ liệu từ log server, dữ liệu máy móc đến video, hình ảnh.
Ví dụ: Amazon S3, Azure Data Lake, HDFS
Khi nào nên sử dụng Data Lake?
- Khi bạn có hỗn hợp dữ liệu (cấu trúc, bán cấu trúc, phi cấu trúc).
- Khi bạn cần lưu trữ dữ liệu linh hoạt, mở rộng và chi phí thấp.
- Phù hợp với phân tích dữ liệu nâng cao, máy học và khám phá dữ liệu.
Tìm hiểu thêm: Giới Thiệu Về Các Loại Dữ Liệu: Structured, Unstructured, và Semi-Structured
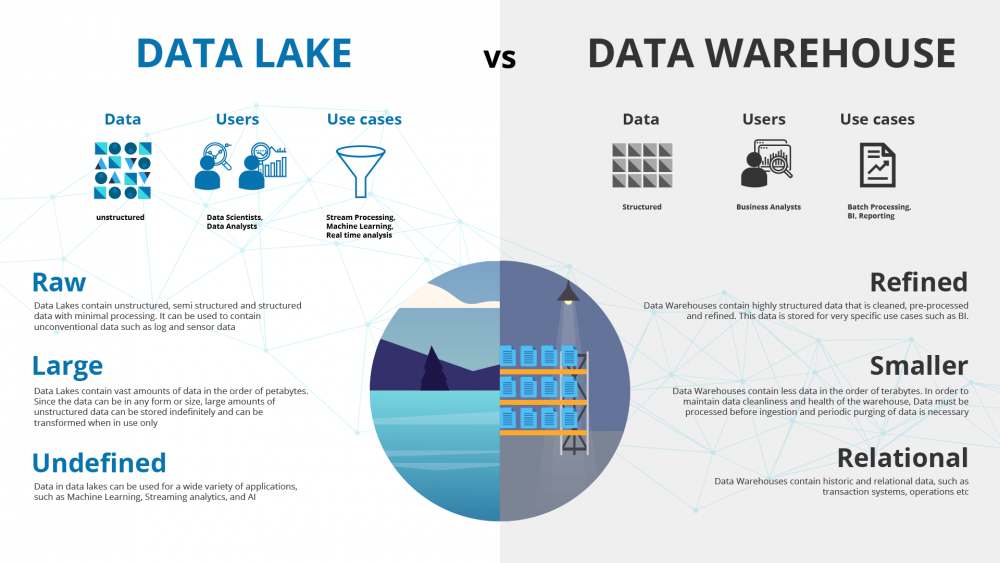
Việc lựa chọn giữa Data Warehouse và Data Lake phụ thuộc vào nhu cầu cụ thể của doanh nghiệp.
Sự Khác Biệt Giữa Data Warehouse và Data Lake
Sự khác biệt giữa Data Warehouse và Data Lake thể hiện rõ qua một số tiêu chí quan trọng.
Cấu trúc dữ liệu
Data Warehouse lưu trữ dữ liệu có cấu trúc, tức là dữ liệu được tổ chức theo một schema cố định từ trước (schema-on-write). Ngược lại, Data Lake lưu trữ dữ liệu ở dạng thô và đa dạng, cho phép xác định schema sau khi dữ liệu được truy xuất (schema-on-read).
Quy trình xử lý dữ liệu
Data Warehouse sử dụng quy trình ETL (Extract, Transform, Load), nghĩa là dữ liệu được trích xuất, biến đổi và sau đó nạp vào hệ thống. Trong khi đó, Data Lake áp dụng quy trình ELT (Extract, Load, Transform), tức là dữ liệu được trích xuất và nạp vào kho lưu trữ trước, sau đó mới được biến đổi khi cần thiết.
Tính linh hoạt
Data Warehouse ít linh hoạt hơn do việc thay đổi cấu trúc dữ liệu đòi hỏi nhiều công sức và tài nguyên. Ngược lại, Data Lake linh hoạt hơn, cho phép dễ dàng thay đổi cấu trúc dữ liệu mà không cần tái cấu trúc toàn bộ hệ thống.
Chi phí
Data Warehouse thường đắt đỏ hơn vì cần nhiều tài nguyên và công cụ để duy trì và tối ưu hóa dữ liệu. Trong khi đó, Data Lake có chi phí thấp hơn, nhưng chi phí này có thể tăng lên nếu khối lượng dữ liệu lưu trữ rất lớn.
Ứng dụng
Data Warehouse thích hợp cho phân tích kinh doanh và báo cáo, trong khi Data Lake phù hợp cho phân tích nâng cao, máy học và lưu trữ dữ liệu lớn, đáp ứng các nhu cầu đa dạng trong việc khám phá và xử lý dữ liệu.
Kết Hợp Data Warehouse và Data Lake
Một xu hướng phổ biến hiện nay là sử dụng Data Lakehouse, kết hợp ưu điểm của cả Data Warehouse và Data Lake. Data Lakehouse hỗ trợ cả dữ liệu có cấu trúc và phi cấu trúc, cung cấp khả năng phân tích chi tiết và nhiệm vụ máy học.
Ví dụ: AWS Lake Formation với S3 và Redshift Spectrum: Một giải pháp kết hợp, sử dụng S3 để lưu trữ dữ liệu thô và Redshift Spectrum để truy vấn dữ liệu như một kho dữ liệu.
Lời Kết
Việc lựa chọn giữa Data Warehouse và Data Lake phụ thuộc vào nhu cầu cụ thể của doanh nghiệp. Nếu bạn cần truy vấn nhanh và phức tạp trên dữ liệu có cấu trúc, hãy chọn Data Warehouse. Ngược lại, nếu bạn cần lưu trữ linh hoạt với nhiều loại dữ liệu và khả năng mở rộng, Data Lake là lựa chọn phù hợp.
Hy vọng bài viết đã giúp bạn hiểu rõ hơn về hai khái niệm này và có thể áp dụng trong các dự án dữ liệu của mình.
Bài viết liên quan

Bài 1 - Giới Thiệu Về Các Loại Dữ Liệu: Structured, Unstructured, và Semi-Structured
Bắt Đầu
Bài 2 - 3 Đặc Tính Của Dữ Liệu: Khối Lượng, Tốc Độ và Đa Dạng
Bắt Đầu
Bài 3 - Sự Khác Biệt Giữa Data Warehouse và Data Lake
Bắt Đầu
Bài 4 - Hiểu về Data Mesh: Xu Hướng Mới Trong Data Engineering
Bắt Đầu
Bài 5 - ETL và ELT: Hiểu Rõ Quy Trình Xử Lý Dữ Liệu Trong Data Warehouse và Data Lake
Bắt Đầu
Bài 6 - Các Nguồn Dữ Liệu và Định Dạng Dữ Liệu Quan Trọng trong Xử Lý Dữ Liệu
Bắt Đầu
Bài 7 - Mô hình dữ liệu – các khái niệm về Star Schema, Data Lineage và Schema Evolution
Bắt Đầu
Bài 8 - Tối ưu hóa hiệu suất cơ sở dữ liệu: Các kỹ thuật quan trọng để truy vấn nhanh và lưu trữ hiệu quả
Bắt Đầu
Bài 9 - Phương Pháp Lấy Mẫu Dữ Liệu (Data Sampling): Khái Niệm, Tầm Quan Trọng và Ứng Dụng
Bắt Đầu
Bài 10 - Hiểu về “Data Skew” (độ lệch dữ liệu) trong hệ thống phân tán
Bắt Đầu