Tối ưu hóa hiệu suất cơ sở dữ liệu: Các kỹ thuật quan trọng để truy vấn nhanh và lưu trữ hiệu quả
Tìm hiểu các kỹ thuật tối ưu hóa cơ sở dữ liệu quan trọng như indexing, partitioning, và compression để cải thiện hiệu suất truy vấn, giảm chi phí lưu trữ và tăng tốc độ truyền tải dữ liệu.

Khi quản lý một lượng lớn dữ liệu, hiệu suất luôn là yếu tố quan trọng. Các truy vấn cơ sở dữ liệu chậm có thể gây ra sự chậm trễ, làm người dùng thất vọng và tổng thể là sự thiếu hiệu quả. Để tránh những vấn đề này, việc hiểu và áp dụng các kỹ thuật tối ưu hóa cơ sở dữ liệu là rất cần thiết.
Trong bài viết này, chúng ta sẽ đi sâu vào ba kỹ thuật quan trọng để cải thiện hiệu suất của cơ sở dữ liệu: indexing, partitioning và compression.
Tìm hiểu thêm: Cơ sở dữ liệu là gì? Các khái niệm cơ bản
Indexing: Chìa khóa để truy vấn nhanh
Công cụ đầu tiên và quan trọng nhất trong chiến lược tối ưu hóa cơ sở dữ liệu là indexing. Nếu không có chỉ mục đúng, cơ sở dữ liệu có thể phải thực hiện full table scan, nghĩa là phải kiểm tra từng dòng dữ liệu một để tìm kiếm thông tin cần thiết. Điều này rất chậm, đặc biệt khi làm việc với dữ liệu lớn.
Indexing là một cấu trúc dữ liệu giúp cải thiện tốc độ truy xuất dữ liệu trong cơ sở dữ liệu.
Bạn có thể tưởng tượng nó như một mục lục trong sách. Thay vì lật qua từng trang của cuốn sách để tìm một từ cụ thể, bạn chỉ cần tra cứu từ đó trong mục lục và đi thẳng đến trang có thông tin bạn cần.
Việc tạo chỉ mục đúng cách cho cơ sở dữ liệu có thể:
- Tăng tốc truy vấn: Cơ sở dữ liệu có thể nhanh chóng tìm kiếm các dòng dữ liệu phù hợp với tiêu chí truy vấn mà không cần quét toàn bộ bảng.
- Đảm bảo tính toàn vẹn dữ liệu: Các chỉ mục có thể giúp duy trì tính duy nhất và toàn vẹn của dữ liệu. Ví dụ, các khóa chính (primary keys) và các ràng buộc duy nhất (unique constraints) thường sử dụng chỉ mục để đảm bảo tính duy nhất của dữ liệu.
- Phát hiện vấn đề sớm: Nếu bạn cố gắng tạo một chỉ mục trên dữ liệu có sự xung đột (ví dụ, cố gắng chỉ mục các giá trị trùng lặp), cơ sở dữ liệu có thể cảnh báo bạn về vấn đề này.
Partitioning: Phân chia dữ liệu để tối ưu hóa quét
Một kỹ thuật tối ưu hóa quan trọng khác là partitioning. Khi bạn có một lượng lớn dữ liệu, việc phân chia chúng thành các phần nhỏ hơn có thể giúp giảm số lượng dữ liệu cần quét khi truy vấn.
Partitioning là quá trình chia dữ liệu thành các phân vùng nhỏ hơn, giúp tối ưu hóa hiệu suất khi cần truy vấn.
Chẳng hạn, nếu dữ liệu của bạn rất lớn và bạn thường xuyên truy vấn theo thời gian, bạn có thể phân vùng dữ liệu theo ngày, tháng, hoặc năm. Điều này giúp giảm thiểu việc phải quét toàn bộ bảng khi chỉ cần tìm dữ liệu của một khoảng thời gian cụ thể.
Ví dụ, nếu bạn lưu trữ dữ liệu giao dịch và chỉ thường xuyên truy vấn các giao dịch trong tháng trước, bạn có thể phân vùng dữ liệu theo tháng. Khi thực hiện truy vấn, cơ sở dữ liệu chỉ cần quét một phân vùng duy nhất thay vì toàn bộ dữ liệu.
Lợi ích của partitioning:
- Giảm lượng dữ liệu cần quét: Khi dữ liệu được phân vùng hợp lý, bạn có thể giảm thiểu số lượng dữ liệu cần quét khi truy vấn.
- Quản lý vòng đời dữ liệu: Việc phân vùng giúp bạn dễ dàng lưu trữ và xóa các phân vùng dữ liệu cũ hơn khi không còn cần thiết, tiết kiệm chi phí lưu trữ và đáp ứng các yêu cầu về tuân thủ.
- Hỗ trợ xử lý song song: Với các phân vùng, cơ sở dữ liệu có thể xử lý chúng song song, tăng tốc độ truy vấn và phân tích dữ liệu.
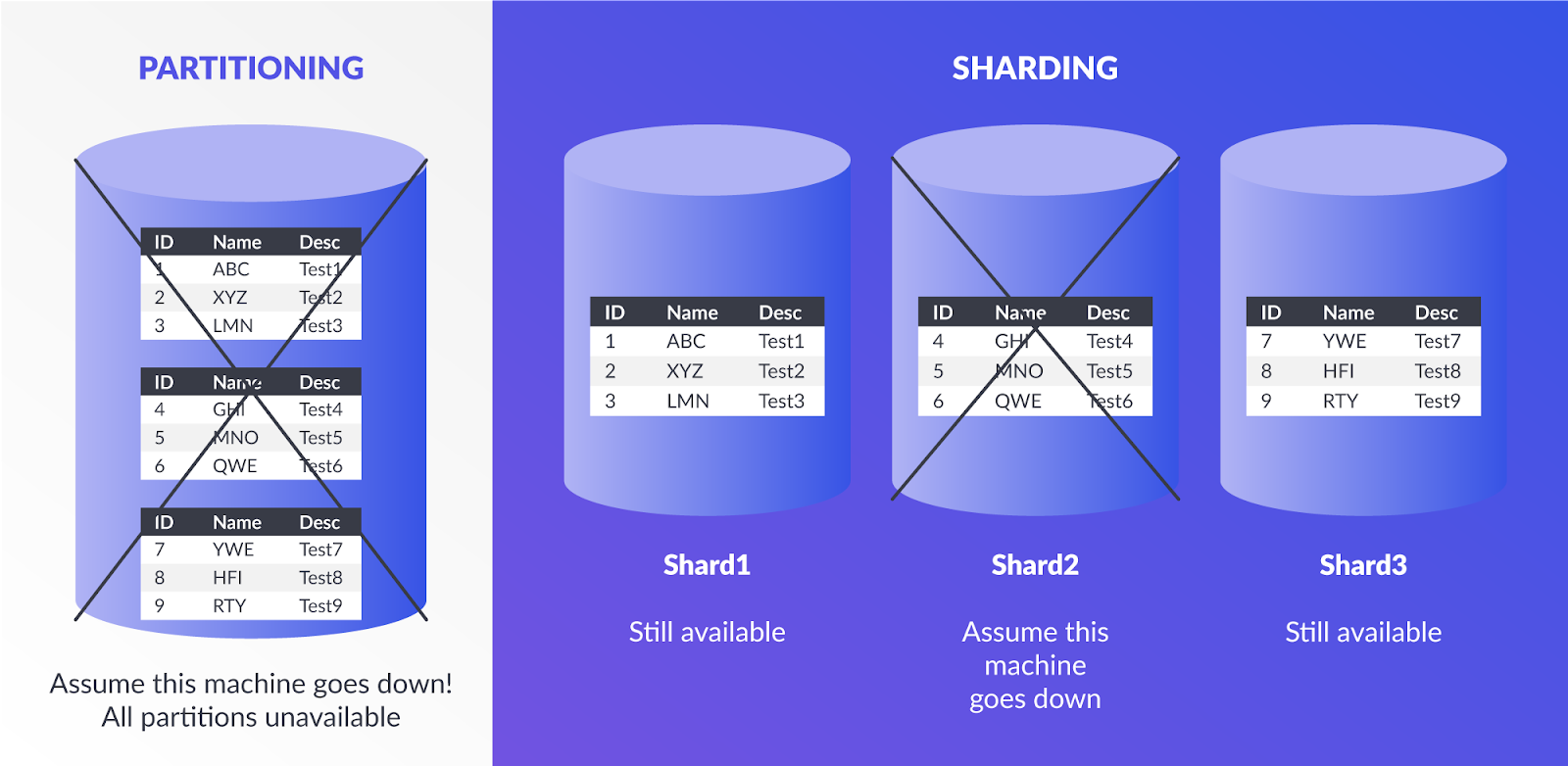
Khi bạn có một lượng lớn dữ liệu, việc phân chia chúng thành các phần nhỏ hơn có thể giúp giảm số lượng dữ liệu cần quét khi truy vấn.
Compression: Nén dữ liệu để giảm thiểu chi phí lưu trữ và tăng tốc độ truyền tải
Compression là một kỹ thuật khác giúp cải thiện hiệu suất cơ sở dữ liệu, đặc biệt khi cơ sở dữ liệu bị IO-bound (bị giới hạn bởi tốc độ nhập/xuất dữ liệu từ đĩa). Việc nén dữ liệu giúp giảm bớt dung lượng cần lưu trữ và có thể giảm thiểu chi phí truyền tải dữ liệu qua mạng.
Compression là quá trình giảm kích thước của dữ liệu bằng cách sử dụng các thuật toán nén. Việc nén dữ liệu giúp giảm thiểu dung lượng lưu trữ, đồng thời tăng tốc quá trình truyền tải và giảm chi phí disk I/O.
Các định dạng nén phổ biến bao gồm GZIP, LZOP, BZIP2, và Zstandard. Mỗi định dạng nén có những ưu nhược điểm riêng, tùy thuộc vào mức độ nén và tốc độ giải nén. Ví dụ, GZIP thường cho tỷ lệ nén cao nhưng có thể chậm hơn khi giải nén, trong khi Zstandard lại có tốc độ giải nén nhanh hơn.
Ngoài ra, khi lưu trữ dữ liệu theo columnar format như Parquet, bạn có thể thực hiện nén theo từng cột. Điều này có thể hiệu quả hơn so với việc nén toàn bộ dòng dữ liệu, bởi vì dữ liệu trong cùng một cột thường có kiểu dữ liệu giống nhau và có thể nén tốt hơn.
Lợi ích của compression:
- Giảm chi phí lưu trữ: Dữ liệu nén sẽ chiếm ít dung lượng hơn, giúp giảm chi phí lưu trữ.
- Tăng tốc độ truyền tải: Dữ liệu nén có thể được truyền tải nhanh hơn, giúp cải thiện hiệu suất khi làm việc với các hệ thống phân tán hoặc khi truyền tải qua mạng.
- Giảm thiểu disk I/O: Việc nén dữ liệu giúp giảm tải cho đĩa cứng, đặc biệt khi cơ sở dữ liệu bị giới hạn bởi tốc độ nhập/xuất dữ liệu.
Kết luận
Việc tối ưu hóa cơ sở dữ liệu là một bước quan trọng để đảm bảo các truy vấn và thao tác trên dữ liệu diễn ra nhanh chóng và hiệu quả. Ba kỹ thuật cơ bản mà bạn nên áp dụng là indexing, partitioning, và compression. Mỗi kỹ thuật này đều có những lợi ích và ứng dụng riêng, giúp cải thiện hiệu suất truy vấn, giảm thiểu chi phí lưu trữ và xử lý dữ liệu.
Hy vọng rằng bài viết này sẽ giúp bạn hiểu rõ hơn về các kỹ thuật tối ưu hóa cơ sở dữ liệu và cách áp dụng chúng để nâng cao hiệu quả làm việc với dữ liệu của mình.
Tìm hiểu thêm: Hướng Dẫn Ứng Dụng Dữ Liệu Trong Doanh Nghiệp SMEs Để Tăng Cường Hiệu Quả Kinh Doanh
Bài viết liên quan

Bài 1 - Giới Thiệu Về Các Loại Dữ Liệu: Structured, Unstructured, và Semi-Structured
Bắt Đầu
Bài 2 - 3 Đặc Tính Của Dữ Liệu: Khối Lượng, Tốc Độ và Đa Dạng
Bắt Đầu
Bài 3 - Sự Khác Biệt Giữa Data Warehouse và Data Lake
Bắt Đầu
Bài 4 - Hiểu về Data Mesh: Xu Hướng Mới Trong Data Engineering
Bắt Đầu
Bài 5 - ETL và ELT: Hiểu Rõ Quy Trình Xử Lý Dữ Liệu Trong Data Warehouse và Data Lake
Bắt Đầu
Bài 6 - Các Nguồn Dữ Liệu và Định Dạng Dữ Liệu Quan Trọng trong Xử Lý Dữ Liệu
Bắt Đầu
Bài 7 - Mô hình dữ liệu – các khái niệm về Star Schema, Data Lineage và Schema Evolution
Bắt Đầu
Bài 8 - Tối ưu hóa hiệu suất cơ sở dữ liệu: Các kỹ thuật quan trọng để truy vấn nhanh và lưu trữ hiệu quả
Bắt Đầu